Way back in 2020 I’d detailed how I’d setup a Tanzu Kubernetes Grid 1.1 management cluster with OpenID Connect support (for single sign-on) before installing Kubeapps with single sign-on on that management cluster.
Recently TKG 1.3 was released and the identity management support in TKG has changed significantly, so it’s time to see what’s different when setting up a TKG cluster with identity management as well as how we can run Kubeapps on TKG 1.3 with identity management. You will of course need to work through the TKG 1.3 documentation for your environment, I’ll just highlight the significant points and small issues that I needed to work around, due to my environment.
This series of two post details the steps that I took to enable Kubeapps running on a TKG 1.3 cluster on AWS configured to allow users to access via the configured identity management:
- This post focuses on the TKG 1.3 setup required to get a workload clusters with identity management (using your chosen identity provider),
- the followup post details the related Kubeapps installation and configuration on TKG 1.3.
Setting up a TKG 1.3 management cluster with identity management
An all new tanzu CLI
The first difference is that we no longer use the tkg CLI, but rather a new integrated tanzu CLI which you will need to ensure is installed and ready to use on your system. It seems that the tanzu CLI is a move towards a single CLI experience for all things Tanzu - good move!
Setting up identity management - AKA single sign-on
Identity management is where TKG has changed quite significantly between TKG 1.1 and TKG 1.3. Previously, TKG workload clusters were configured at creation time with OIDC parameters for the Dex instance running on your management cluster, and the management cluster itself did not enable direct access via identity management at all. With TKG 1.3, the new VMware Pinniped project is being used so that identity management can be configured and updated at runtime and is also supported for accessing the management cluster.
It’s worth reading through the Enabling identity management docs to understand the new setup as well as create your oauth2 client id with your chosen identity provider (I’m using google in this example below, the docs recommend Okta)
Creating your TKG 1.3 management cluster
I initially had errors when trying to create a management cluster on AWS, both via the --ui as well as via the console. It turned out that even though I’d used the ui installer and selected the “Automate creation of AWS CloudFormation stack” checkbox, the required profiles still did not exist, so my (later) console-based install attempts would fail with:
|
|
Checking the logs as suggested indicated that the expected AWS InstanceProfiles didn’t exist:
|
|
Sure enough, if I then checked what InstanceProfiles exist within my account, I could see that similar but not the same profiles existed:
|
|
For example, the error was because the InstanceProfile control-plane.tkg.cloud.vmware.com did not exist, whereas control-plane.cluster-api-provider-aws.sigs.k8s.io did exist. It turns out the existing InstanceProfiles were from last year when I installed TKG 1.1 and the required ones for 1.3 were, for reasons still not known to me, not yet present. A helpful TKG expert pointed me to the manual TKG 1.3 management cluster install on AWS instructions, specifically the instructions to create the CloudFormation stack on AWS.
When following those instructions, I had to include the AWS_REGION env var even though it was specified in my aws credentials file, but it did the trick:
|
|
With the correct profiles created, I was then able to get a management cluster running, though with a small issue.
Tagging an AWS subnet
While following the configuring identity management after management cluster deployment doc I noticed that although my management cluster was created, some of the services were unable to be setup as load balancers:
|
|
I’d hit this before when trying TKG 1.1 and once again, the reason it happened was that I’d initially selected the UI option for the TKG installer to create a new VPC, but after my initial install failed, I’d chosen to re-use that VPC (actually re-using the complete cluster config other than changing the name) when retrying, which meant that VPC subnets were not tagged with my new cluster name.
To fix this, I again navigated to the list of subnets for the region, for example, for us-east-1 you will find the list at https://console.aws.amazon.com/vpc/home?region=us-east-1#subnets:sort=desc:tag:Name. In this list you will see a -public and -private subnet prefixed by the name of your management cluster, for example, in my case I see:
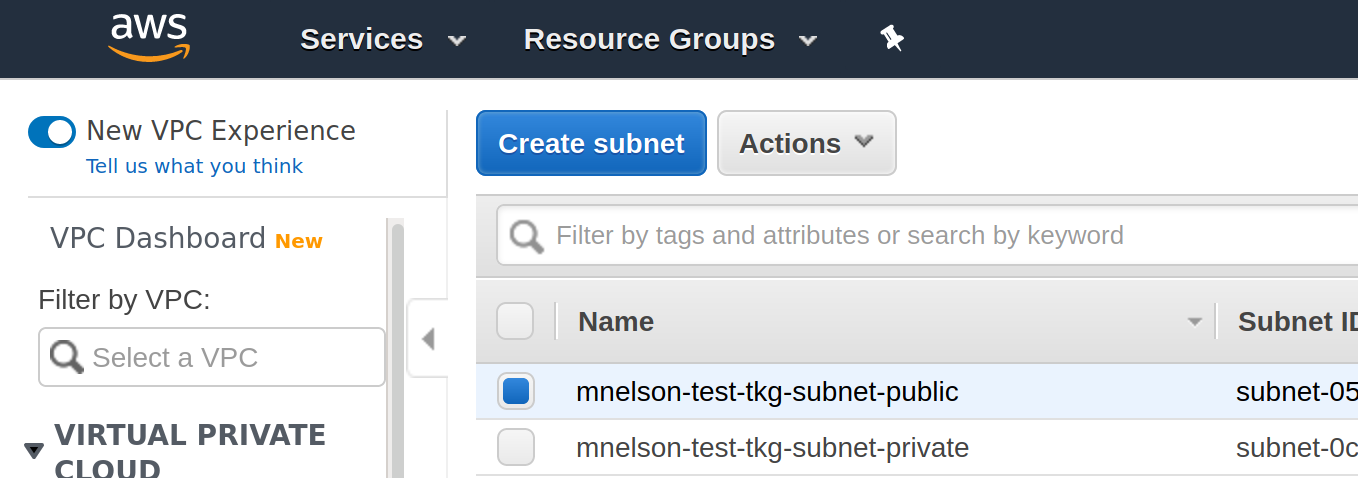
If you click on the first subnet, the public one, the details will be displayed including a Tags tab. Click on the Tags tab and you should see that the subnet includes a tag for your management cluster, but in my case, it was for a previously failed management cluster name. I edited the tag to use the correct cluster name and after a few minutes the service had a load balancer.
Ensuring the pinniped post-deploy job succeeds
With the load balancer now set I was able to continue following the configuration of identity management after management cluster deployment documentation and update the callbacks in my identity provider, but I was unable to generate a kubeconfig for use with my configured identity provider, instead getting the error:
|
|
Checking the pinniped pods showed that pinniped runs a post-deploy job which depends on the pinniped supervisor load balancer being available, which in my case, had not been available at the time the job ran due to the missing subnet tags identified above. So this post-deploy job had exceeded the backoff limit (of 6 failures) while I as fixing the subnet tag and was no longer retrying.
To fix this, I edited the job to have a larger backoff limit (of 7), waited a few minutes and saw the job then complete successfully:
|
|
I was then able to successfully authenticate via kubectl using my google account identity, following the instructions at the end of the configuration of identity management after management cluster deployment documentation to add a role-binding for my user.
So, management cluster complete with only a few environment-specific hiccups along the way!
Setting up a TKG 1.3 workload cluster with identity management
Creating a workload cluster was as simple as copying the config that I’d just used successfully for the management cluster, changing the CLUSTER_NAME only, and then:
tanzu cluster create --file ~/.tanzu/tkg/clusterconfigs/workload.yaml
though check the full documentation for details.
I then used very similar commands to grab an admin kubeconfig (ie. one that is setup with cert-based authentication, not using the identity management) for my new workload cluster:
tanzu cluster kubeconfig get kubeapps-tkg-13-workload-test --admin
and used that to verify for myself that the Kubernetes api server of the workload cluster in TKG 1.3 no longer sets any of the --oidc-* flags, instead it’s Pinniped all the way down. Pinniped is already installed and configured on the workload cluster, so last of all, I created a non-admin kubeconfig (ie. one which will use the identity management):
tanzu cluster kubeconfig get kubeapps-tkg-13-workload-test --export-file /tmp/id_workload_test_kubeconfig
and then verified that, after creating a role-binding, I am able to use the cluster using my google identity:
kubectl create clusterrolebinding id-workload-test-rb --clusterrole cluster-admin --user [email protected]
kubectl get pods -A --kubeconfig /tmp/id_workload_test_kubeconfig
Success. Now we’re ready to install Kubeapps on the workload cluster…